Universal Embeddings of text data have been widely used in natural language processing. It involves encoding words or sentences into fixed length numeric vectors which are pre-trained on a large text corpus and can be used to improve the performance of other NLP tasks (like classification, translation).
While word embeddings have been massively popular and successful, efforts to obtain embeddings of larger chunks of text (like sentences) have not been as successful. Approaches to learning sentence embeddings using unsupervised methods (like SkipThought or FastSent) have not given satisfactory results.
In this blog post, I will give you a walkthrough of a recent paper (Supervised Learning of Universal Sentence Representations from Natural Language Inference Data) published by the Facebook research team that employs a supervised method to learn sentence embeddings.
Introduction
The authors describe solutions to two important questions that arise in building a sentence embedding model – the type of task to be used for training the sentence vectors and the preferable neural network architecture to use to generate sentence encodings.

The authors, first, generate sentence vectors using a sentence encoding architecture and word vectors as input. This encoder is then followed by a classifier that takes the encoded sentences as input and trains the sentence vectors.
They show that sentence embeddings generated from models trained on a natural language inference classifier (more details below) give best results in terms of accuracy on downstream tasks. They also explore a number of different architectures for sentence encoding. Namely, standard recurrent models such as LSTMs and GRUs, a self-attentive network and a hierarchical convolutional network. We will go through each of these implementations in detail.
The Natural Language Inference task
Natural language inference, also known as recognizing textual entailments aims at finding a directional relationship between text fragments. In this framework, the entailing and entailed texts are termed text (t) and hypothesis (h), respectively. And, “t entails h” (t => h) if, typically, a human reading t would infer that h is most likely true. (Source).

For this task, the authors use the SNLI (Stanford Natural Language Inference) dataset. It consists of 570k human generated English sentence pairs, manually labeled with one of the three categories – entailment, contradiction and neutral. The authors believe that the semantic nature of this task makes it a good candidate to learn sentence representations that capture universally useful features.
The Neural Network Architecture
There are two parts of the neural network architecture.
- The first part is a shared encoder that encodes both the sentences into vectors.
- The second part takes as input the sentence vectors generated in the first part and predicts one of the three labels using a 3-class classifier.
Let’s go through both the parts of the network in detail.
Sentence Encoder Architectures
The authors explore 7 different architectures for sentence encoding. Let’s go through these networks one by one.
LSTM and GRU
These are the simplest encoders used. As we know, we get n number of hidden representations (vectors) for a sequence of n words in an LSTM or GRU network. A sentence, in this case, is represented by the last hidden vector.
The authors use another variant of this method, called BiGRU-last. In this method, the last hidden state of a forward GRU and the last hidden state of a backward GRU is concatenated to form the sentence vector.
BiLSTM with mean/max pooling
For a sequence of n words, a bi-directional LSTM computes a set of n vectors and each vector is a concatenation of a forward LSTM and a backward LSTM that read the sentence in opposite directions. The authors employ two strategies – selecting maximum value over each dimension of the hidden units (max-pooling) or by considering the average of each dimension (mean-pooling).

Self-attentive network
The self-attentive sentence encoder uses an attention mechanism over the hidden states of a BiLSTM to generate a representation of the sentence vector. This method uses the context vectors which are generated using a weighted linear combination of the hidden vectors. The self-attentive network has multiple views of the input sentence and we get 4 context vectors. The final sentence representation is the concatenation of these 4 context vectors.
If you are interested in knowing the details of the attention mechanism, here is an awesome introduction by Andrew Ng.

Hierarchical ConvNet
The hierarchical convolutional network introduced comprises 4 convolutional layers. At every layer, max-pooling of the feature maps is done to obtain a representation. The final sentence embedding is represented by a concatenation of the 4 max-pooled representations.
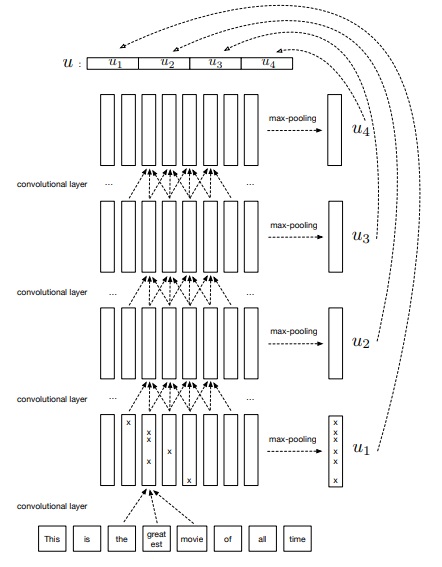
NLI Classifier Architecture
Now that we have discussed the various sentence encoding architectures used in the paper, let’s go through the part of the network which takes these sentence embeddings and predicts the output label.

After the sentence vectors are fed as input to this model, 3 matching methods are applied to extract relations between the text, u and hypothesis, v –
- concatenation of the two representations (u, v)
- element-wise product u * v
- and, absolute element-wise difference |u – v |
The resulting vector captures information from both the text, u and the hypothesis, v, and is fed into a 3-class classifier consisting of multiple fully connected layers followed by a softmax layer.
Training Details
- Stochastic gradient descent (SGD) is used with a learning rate of 0.1 and a weight decay of 0.99.
- At each epoch, the learning rate is divided by 5 if the dev accuracy decreases.
- Mini-batches of size 64 is used, and training is stopped when learning rate goes beyond the threshold of 1e-5.
- For the classifier, multi-layer perceptron with 1 hidden-layer of 512 hidden units is used.
- GloVe vectors have been used for pre-trained word embeddings. These vectors have been trained on Common Crawl 840B with 300 dimensions. A more recent version of InferSent, know as InferSent2 has been trained on fastText vectors.
All these details are the same for all the models trained on SNLI.
Evaluation of Sentence Embeddings
The authors evaluate the quality of the sentence representation by using them as features in 12 different transfer tasks. They have also constructed a sentence evaluation tool called SentEval to automate evaluation of all the tasks mentioned in the paper. The tool uses Adam to fit a logistic regression classifier, with batch size 64.
Results
Impact of the sentence encoding architectures
The authors found that different models trained on the same NLI corpus lead to different transfer task results. The BiLSTM with the max-pooling operation performs best on both SNLI and transfer tasks. The transfer task accuracy has been measured by taking the micro and macro averages of the 12 transfer tasks.
Better performance on the training NLI task is not always followed by a better performance on the transfer task.
The authors hypothesize that some models are likely to over-specialize and adapt too well to the biases of a dataset without capturing general-purpose information of the input sentence. The difference between the results seems to come from the different
abilities of the models to incorporate general information while not focusing too much on specific features useful for the task at hand.
Optimization Algorithm
The transfer quality was also found to be influenced by the optimization algorithm. They found that the BiLSTM-max converged faster on SNLI (5 epochs instead of 10), but obtained worse results on the transfer task.
Embedding Size
Increasing embedding sizes lead to increased performance for almost all the models. This was particularly true for models like – BiLSTM-Max, HConvNet, inner-att.
Comparison with SkipThought
The best performing sentence encoder before InferSent is the SkipThought-LN model. It has been trained on a large corpus of ordered sentences (64 million sentences). The InferSent model outperforms the results obtained by the SkipThought vectors.
NLI as a supervised training set
The findings indicate that the model trained on SNLI obtains much better overall results than models trained on other supervised tasks such as COCO, dictionary definitions, NMT, PPDB, and SST.
Some Useful Resources
- The InferSent encoder is publicly available. You can find it here.
- If you are interested in the current state of the art methods of word and sentence embeddings, you should definitely check out this awesome post – The Current Best of Universal Word Embeddings and Sentence Embeddings.
- If you want some background on word embedding developments before 2017, you should have a look at this – Word embeddings in 2017.
- If you are interested in transfer learning, you should check out the recent work of Jeremy Howard and Sebastian Ruder on ULMFiT (here and here).
I hope you found the post useful. Thanks a lot. 🙂

how this techique can be used to compare the similarity betwen two different text(ciontaining multiple words)
LikeLike
*multiple sentences
LikeLike